 一、引言
一、引言
声音,作为我们日常生活中不可或缺的一部分,承载着丰富的信息和情感。随着科技的进步,声音已经从模拟时代迈入了数字时代。声音数字化过程,即将模拟声音信号转换为数字信号,是数字音频技术的基础。本文将详细介绍声音数字化的过程,以及与之相关的关键概念和技术。
二、声音数字化过程概述
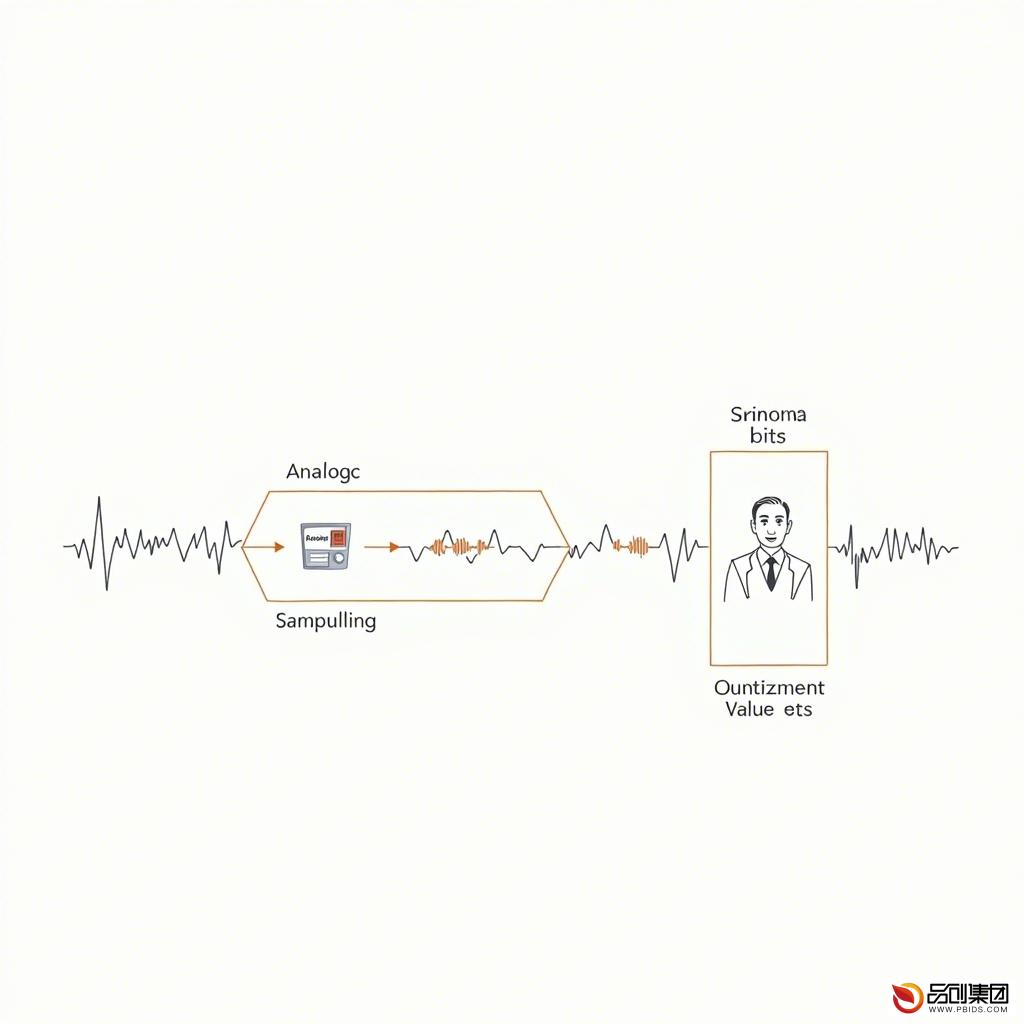
声音数字化过程主要包括采样、量化和编码三个步骤。这三个步骤共同决定了数字音频的质量和特性。
- 采样
采样是将连续变化的模拟声音信号转换为离散时间点的信号的过程。采样率决定了数字音频的频率分辨率,即能够表示的最高频率。采样率越高,数字音频的频率分辨率越高,音质越好。常见的采样率有44.1kHz、48kHz、96kHz等。
- 量化
量化是将采样后的离散信号转换为有限数量的离散值的过程。量化位数决定了数字音频的幅度分辨率,即能够表示的音量级别数量。量化位数越高,数字音频的幅度分辨率越高,音质越好。常见的量化位数有16位、24位等。
- 编码
编码是将量化后的离散值转换为二进制数字信号的过程。编码格式决定了数字音频的存储和传输方式。常见的编码格式有PCM(脉冲编码调制)、MP3、AAC等。不同的编码格式在音质、压缩率和兼容性方面有所不同。
三、声音数字化过程中的关键技术
在声音数字化过程中,涉及许多关键技术,这些技术对数字音频的质量和特性产生重要影响。
- 抗混叠滤波器
抗混叠滤波器是在采样前对模拟声音信号进行预处理的关键技术。它的作用是滤除高于采样率一半的频率成分,防止混叠现象的发生。混叠现象会导致数字音频在重建模拟信号时出现失真。
- 抖动技术
抖动技术是在量化过程中引入微小随机误差的方法。它的作用是改善量化噪声的分布,使量化噪声在听觉上更加平滑,从而提高数字音频的音质。
- 心理声学模型
心理声学模型是利用人类听觉系统的特性来优化数字音频编码的关键技术。它通过分析人类听觉系统的掩蔽效应、频率分辨率等特性,来确定哪些频率成分可以被压缩或省略而不影响音质。心理声学模型的应用可以显著提高数字音频的压缩率,同时保持较好的音质。
四、声音数字化技术的应用与发展
声音数字化技术在音频处理、通信、娱乐等领域具有广泛的应用。随着技术的不断发展,声音数字化技术也在不断创新和完善。
- 高清音频技术
高清音频技术是指采样率、量化位数和编码格式等方面均达到较高标准的数字音频技术。高清音频技术能够提供更加逼真、细腻的音质体验,满足人们对高品质音乐的需求。
- 音频识别与合成技术
音频识别与合成技术是利用机器学习、深度学习等人工智能技术对声音进行识别、分析和合成的技术。这些技术在语音识别、语音合成、音乐创作等领域具有广泛的应用前景。
- 音频传输与存储技术
音频传输与存储技术是指将数字音频信号进行高效传输和存储的技术。随着云计算、大数据等技术的发展,音频传输与存储技术也在不断创新和完善,为数字音频的广泛应用提供了有力支持。
五、结论
声音数字化过程是将模拟声音信号转换为数字信号的关键技术。通过采样、量化和编码等步骤,声音可以被数字化并在数字世界中传输、存储和再现。声音数字化技术在音频处理、通信、娱乐等领域具有广泛的应用前景。随着技术的不断发展,声音数字化技术也在不断创新和完善,为人们提供更加逼真、细腻、高效的音质体验。