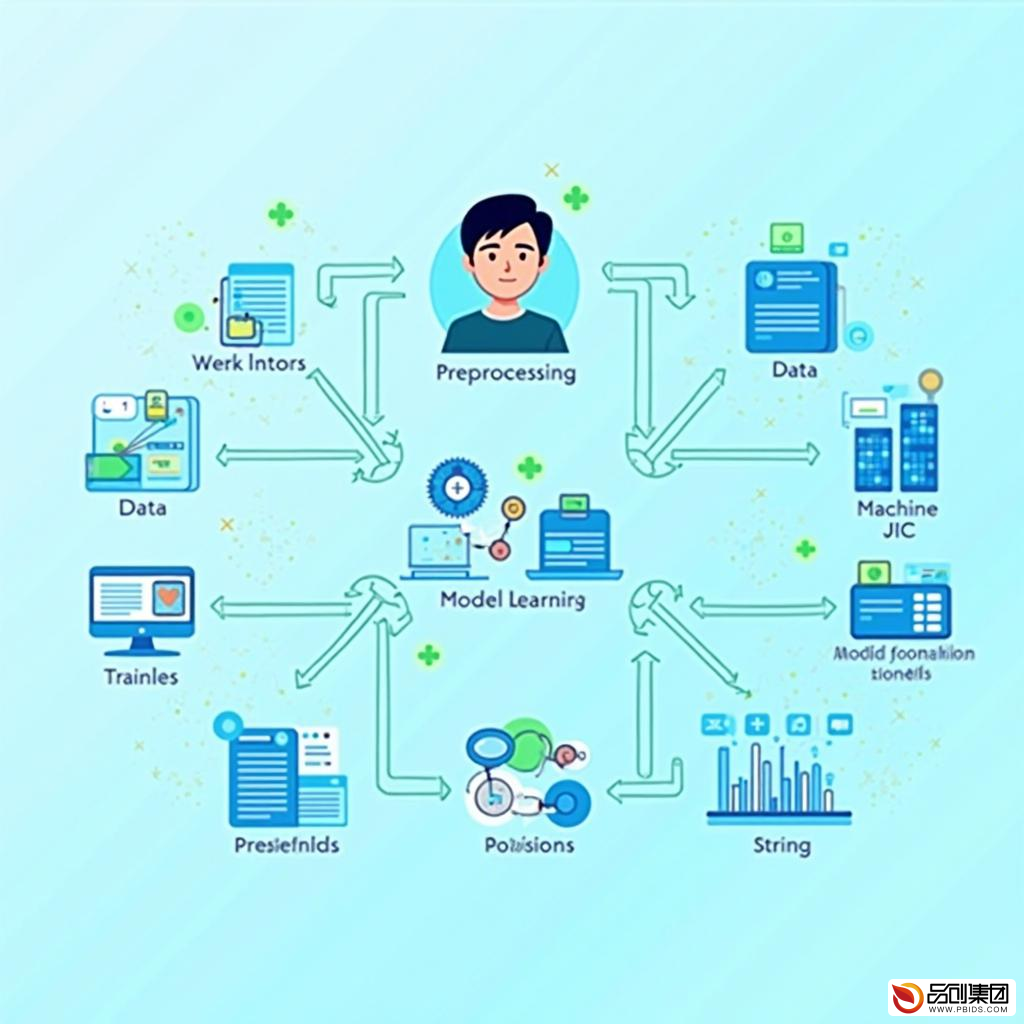
 在人工智能与机器学习的浪潮中,模型训练作为核心环节,其效果直接决定了智能系统的性能与表现。而数据,作为模型训练的“燃料”,其质量与处理方式对最终成果有着不可估量的影响。本文将聚焦于模型训练所需的数据预处理服务,从重要性、流程、技术与方法等多个维度进行深入剖析。
在人工智能与机器学习的浪潮中,模型训练作为核心环节,其效果直接决定了智能系统的性能与表现。而数据,作为模型训练的“燃料”,其质量与处理方式对最终成果有着不可估量的影响。本文将聚焦于模型训练所需的数据预处理服务,从重要性、流程、技术与方法等多个维度进行深入剖析。
一、数据预处理:模型训练的基石
数据预处理,是指在将数据输入模型训练之前,对数据进行的一系列处理操作,旨在提升数据质量,使其更适合于模型的学习与分析。这一过程对于提高模型准确率、减少过拟合、加速训练等方面具有至关重要的作用。
二、数据预处理服务流程
- 数据收集:从各种来源(如数据库、API、网络爬虫等)收集原始数据,确保数据的多样性与全面性。
- 数据清洗:去除重复、缺失、异常或无效数据,修正错误值,确保数据的准确性与完整性。
- 数据标注:对文本、图像等非结构化数据进行人工或自动标注,为模型提供明确的监督信号。
- 数据增强:通过旋转、缩放、翻转等操作增加数据多样性,提高模型的泛化能力。
- 数据归一化/标准化:将数据缩放到同一尺度,消除不同特征间的量纲差异,加速模型收敛。
- 特征选择:从原始特征中挑选出对模型预测最有价值的特征,减少噪声干扰。
- 特征提取:通过降维、聚类等技术提取数据的深层特征,提高模型的学习效率。
三、关键技术与方法
- 自动化清洗工具:利用正则表达式、机器学习算法等自动化手段,高效处理大规模数据集。
- 半监督学习与无监督学习:在数据标注资源有限的情况下,利用未标注数据进行预训练,提高标注效率。
- 生成对抗网络(GANs):用于数据增强,生成与真实数据分布相近的合成数据,丰富训练样本。
- 主成分分析(PCA)、t-SNE等降维技术:有效减少特征维度,保留数据的主要信息。
- 集成学习方法:结合多个基学习器的预测结果,提高特征选择与提取的稳定性与准确性。
四、数据预处理对模型性能的影响
经过精心预处理的数据,能够显著提升模型的准确率、召回率、F1分数等评价指标。同时,预处理还能有效减少训练时间,降低模型过拟合的风险,使模型更加鲁棒与泛化。
五、案例分享
以图像识别任务为例,通过数据增强技术(如随机裁剪、色彩抖动)处理后的数据集,使得模型在未见过的图像上也能表现出色。而在自然语言处理领域,高质量的数据标注与特征提取技术,则是提升文本分类、情感分析等任务性能的关键。
六、未来展望
随着大数据与人工智能技术的不断发展,数据预处理服务将更加注重自动化、智能化与个性化。未来,我们期待看到更多创新的数据预处理技术与方法,为模型训练提供更加高效、精准的数据支持。